Dieser Blogbeitrag wurde zuerst veröffentlicht unter https://blogs.tib.eu/wp/dini-ag-blog/2020/11/23/softwareloesung-symplectic-elements-mainz/
Mit “Gutenberg Research Elements” führt die Johannes Gutenberg-Universität Mainz ein Forschungsinformationssystem ein, das den Wissenschaftler innen vielfältige Möglichkeiten der Erfassung, Dokumentation und Zusammenführung von Forschungsinformationen bietet und auf diese Weise die Voraussetzungen für den Aufbau darauf basierender Nutzerdienste und einer uniweiten Forschungsberichterstattung schafft. Der vorliegende Werkstattbericht gibt einen Einblick in den Stand der Entwicklungen – von der Systemwahl bis zur Durchführung von Pilotphasen – unter besonderer Berücksichtigung der Datenintegration und der Schnittstellen.
Ausgangssituation
Seit März 2018 arbeiten die Universitätsbibliothek, die Abteilung Forschung und Technologietransfer, die Stabsstelle Planung und Controlling und das Zentrum für Datenverarbeitung der Johannes Gutenberg-Universität Mainz (JGU) daran, das Forschungsinformationssystem „Gutenberg Research Elements“ für die Universität zur Verfügung zu stellen. Die JGU ist eine Volluniversität, die im Berichtsjahr 2019 4.440 wissenschaftliche Mitarbeiter*innen (inkl. Professor*innen) an 10 Fachbereichen, der Kunsthochschule und Hochschule für Musik vereint.
Das Projekt zur Einführung eines Forschungsinformationssystems (FIS) hat zum Ziel, Forschungsinformationen aus unterschiedlichen Datenquellen an der JGU zusammenzuführen und für die Berichterstattung sowie die wissenschaftliche Tätigkeit zur Verfügung zu stellen. Die zukünftige Datenerfassung soll möglichst standardisiert erfolgen, Mehrfacherhebungen vermeiden und Informationen aus bestehenden IT-Systemen miteinander verknüpfen. Bis zum Projektbeginn lagen diese Informationen separat strukturiert und verteilt in verschiedenen Fachanwendungen wie Personal- und Finanzverwaltung, Hochschulbibliographie, Open-Access-Repositorium und Identitätsmanagement (IDM) vor. Bereits in den frühen 1990er Jahren gab es einen ersten Versuch, Informationen zu Personen, Publikationen und Projekten innerhalb eines Systems zu erfassen und darzustellen. Diese eigenentwickelte Forschungsdatenbank unterstützte jedoch aufgrund fehlender Schnittstellen keine übergreifenden Workflows, so dass der Betrieb eingestellt und die Publikationsdaten in das Repositorium der Universitätsbibliothek übernommen wurden. Mit der Inbetriebnahme des FIS wird diese erweiterte Funktion des Repositoriums als Hochschulbibliographie nun abgelöst durch eine modular aufgebaute Gesamtinfrastruktur zum Publikationsdatenmanagement (siehe Abb. 2).
Das Projekt wird im Auftrag der Hochschulleitung und im Rahmen der Einführung von IT-gestützten Softwaresystemen durch den Chief Information Officer der JGU betreut. Das FIS als modularer Bestandteil der Informationsinfrastruktur der JGU soll unter anderem zum Aus- und Aufbau einer zentral angelegten Forschungsberichterstattung dienen. Den entscheidenden Anstoß für die Hochschulleitungsbeschlüsse gab die Empfehlung des Wissenschaftsrates zur Umsetzung des Kerndatensatzes Forschung (KDSF) für die Datenlieferung im Kontext großer Drittmittelanträge und im Rahmen der Exzellenzstrategie. Für die Wissenschaftler*innen der JGU soll durch eine Mehrfachnutzung der Daten, z.B. im Kontext von Antragsstellungen und wissenschaftlichen Veröffentlichungen sowie der automatisierten Übernahme von Inhalten auf Webseiten ein Mehrwert und damit ein Anreiz für die Bereitstellung und Verknüpfung ihrer Forschungsleistungen im FIS gegeben werden.
Auswahl der Softwarelösung
Nach einer vorgelagerten Evaluationsphase unterschiedlicher Systeme fiel die Auswahl auf die britische Softwarelösung “Elements” des Anbieters Symplectic (Teil von Digital Science, einem Unternehmen der Verlagsgruppe Georg von Holtzbrinck GmbH). In den Auswahlprozess waren neben weiteren kommerziellen Systemen auch eine Open-Source-Softwarelösung einbezogen, deren Einsatz an der JGU jedoch aufgrund der erforderlichen Entwicklungskapazitäten verworfen wurde.
Bei der Entscheidung für eine Softwarelösung war die zeitsparende und intuitive Publikationserfassung ein maßgebliches Kriterium. Die früheren Erfahrungen an der JGU zeigten, dass diese Anforderung bei den Forschenden eine hohe Priorität hat und eine unabdingbare Voraussetzung für die Akzeptanz des Forschungsinformationssystems ist. Gefordert waren deshalb insbesondere Schnittstellen zum automatisierten Import von Publikationsdaten aus einer möglichst großen Zahl bibliographischer Datenbanken, eine leistungsfähige Dublettenerkennung, die Möglichkeit für Nutzer*innen, individuell präferierte Importquellen und Anzeigeformate für Publikationen festzulegen und eine Schnittstelle, um Publikationsdaten aus dem FIS automatisiert in externe Anwendungen, bspw. auf die persönliche Homepage, zu übernehmen. Auch die Integrationsfähigkeit des FIS mit Softwarelösungen für Repositorien spielte eine maßgebliche Rolle, da zeitgleich mit dem Projektstart ein Software-Umstieg für das Open-Access-Repositorium “Gutenberg Open Science” der JGU vorbereitet wurde.
Da ein Ausgangspunkt des Projekts in der Bereitstellung von Berichten gemäß dem KDSF lag, bestand eine weitere zentrale Anforderung darin, dass das System diesen Standard unterstützt oder über entsprechend anpassbare Reporting-Mechanismen verfügt. Mit der Auswahl von „Symplectic Elements“ hat sich die Johannes Gutenberg-Universität Mainz für eine Softwarelösung entschieden, die im angloamerikanischen Raum verbreitet eingesetzt wird, für die zum Zeitpunkt des Projektbeginns aber noch keine Anwendungen in der deutschen Forschungs- und Hochschullandschaft vorlagen. Daher wurde mit dem Anbieter eine prototypische Umsetzung des KDSF als Teil des Projekts vereinbart.
Lösungsansätze und Herausforderungen bei der Datenintegration
Bei der ausgewählten Softwarelösung handelt es sich um ein umfangreich konfigurierbares System, das neben den Möglichkeiten für lokale Anpassungen der Nutzeroberfläche auch Änderungen der Datenstrukturen für die verzeichneten Objekte innerhalb des Systems zulässt, bspw. die Metadatenstruktur verschiedener Publikationstypen. Änderungen dieser Art sind jedoch im Rahmen des Projektes bewusst nicht vorgesehen, um die daraus resultierenden Anpassungen an den Schnittstellen zu vermeiden. Bereits in einem frühen Projektstadium konnte somit der Schwerpunkt der Arbeiten auf die Einrichtung der Schnittstellen gelegt werden. Aktuell werden die Daten zu Publikationen (einschließlich Patenten), Projekten, Personen und Organisationseinheiten integriert. Die in Abbildung 1 zusätzlich dargestellten, weiteren Datenbestände wie Preise, Promotionsprogramme u.a. werden in einer späteren Projektphase bearbeitet.
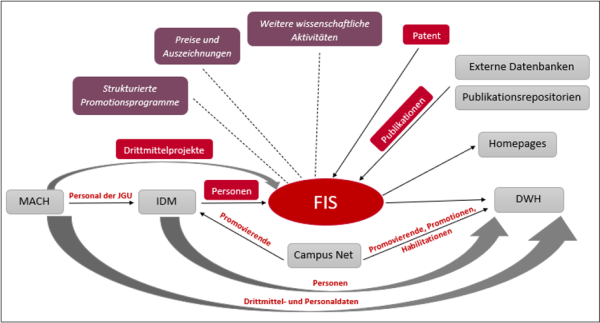
Abbildung 1: Datenbestände zu Forschungsinformationen an der JGU
Publikationen
Über den Import von Publikationsdaten aus Gutenberg Open Science hinaus ist die bidirektionale Integration des Repositoriums in Vorbereitung. Deposits von Volltexten werden über eine SWORD-Schnittstelle vom FIS an das Repositorium übergeben. Dadurch wird es für die Nutzer*innen sehr einfach möglich, für ihre im FIS erfassten Zeitschriftenaufsätze eine Zweitveröffentlichung im Repositorium anzustoßen. Mit dieser Funktion zum “self archiving” soll der grüne Weg des Open Access an der Johannes Gutenberg-Universität gefördert werden, denn die Zahl der Zweitveröffentlichungen im Repositorium ist seit mehreren Jahren konstant niedrig.
Gutenberg Research Elements ist als geschlossenes System, d.h. als interne Arbeitsumgebung für die Wissenschaftler*innen und das Wissenschaftsmanagement an der JGU, vorgesehen. Die öffentliche Darstellung ausgewählter Inhalte, insbesondere der Publikationslisten, ist jedoch aus Sicht der Forschenden entscheidend für ihre Bereitschaft, das System zu nutzen. Deshalb besteht die Möglichkeit, die im FIS gepflegten Publikationslisten auch auf den persönlichen Homepages anzuzeigen. Dies wird über ein Plugin des an der JGU verwendeten Content Management Systems WordPress realisiert. Für eine frei zugängliche Suchfunktion im Sinne einer Universitätsbibliographie kommt Suchmaschinentechnologie (Solr) zum Einsatz. Beide Anwendungen greifen über die REST-Schnittstelle des FIS auf die Publikationsdaten zu und sind aktuell in der Testphase. In einem der nächsten Schritte sollen auch Projekt- und Forschungsdaten auf die Homepages und in die Universitätsbibliographie exportiert werden.
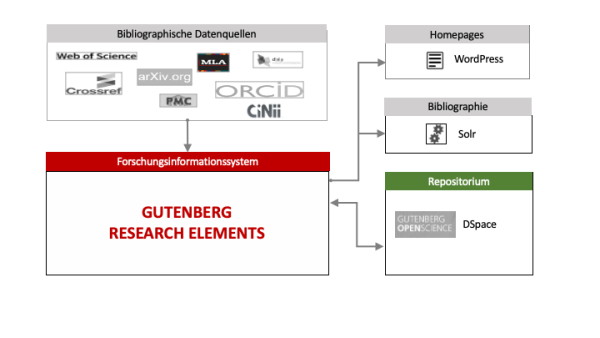
Abbildung 2: Übersichtsschema der Publikationsdaten-Infrastruktur
Projekte
Für die Integration von Informationen über Drittmittelprojekte wurde ein Import aus der JGU-internen Finanzverwaltungssoftware MACH realisiert. Dabei zeigte sich, dass die importierten Informationen nicht immer mit der Perspektive der Forschenden, was als Projekt darzustellen ist, übereinstimmen. Gründe hierfür liegen in der ausschließlichen Eignung der MACH-Software (im Bereich Finanzen) für Verwaltungszwecke im Rahmen von Mittelzuweisungen und Buchungen, wodurch es bei der Übernahme von Projektinformationen in das FIS zu Schwierigkeiten im Hinblick auf deren Nutzung für die Verwaltung von Projektlisten kommt. Grundsätzlich lassen sich zwei Problemfelder unterscheiden: Zum einen gibt es in der Finanzverwaltungssoftware keine eindeutige Zuordnung von einem Projekt zu einem finanziellen Objekt, was die Bündelung mehrerer Objekte zu einem Projekt erforderlich macht. Zum anderen war es bislang für die Arbeitsprozesse an der Universität nicht erforderlich, die Bezeichnungen der Finanzobjekte entlang extern vorgegebener wissenschaftlicher Standards in der Finanzverwaltungssoftware zu erfassen. Dieser Sachverhalt unterstreicht die Notwendigkeit, sich auch über die Grenzen des Projektes hinaus mit weiteren Fachabteilungen abzustimmen, notwendige Anpassungsbedarfe zu identifizieren und im Laufe der Zeit umzusetzen. Aktuell wird diskutiert, wie man Informationen im Operativsystem MACH im Sinne einer Nachnutzung im FIS erfassen kann und ob die Möglichkeit einer manuellen Eintragung von z.B. nicht-drittmittelfinanzierten Projekten im FIS praktikabel ist. Mögliche Lösungen sollen vor dem Hintergrund der dauerhaften Qualitätssicherung und dem Prinzip der Datensparsamkeit innerhalb kleiner Arbeitsgruppen erarbeitet werden.
Personen und Organisationseinheiten
Als anspruchsvolle Anforderung stellt sich die Abbildung der Universitätsstruktur der JGU im FIS auf der Grundlage des universitären IDM dar. Bereits seit Beginn des Projektes wurde dieser Sachverhalt innerhalb der Projektgruppe sowie in Gesprächen mit dem Softwareanbieter eingehend diskutiert. Für die Nutzung des FIS durch Wissenschaftler*innen und das Wissenschaftsmanagement sowie für Datenexporte (bspw. für Publikationslisten) ist die Zuordnung der Objekte zu Organisationseinheiten maßgeblich. Dabei besteht die Hauptschwierigkeit darin, dass die Integration der Organisationsstruktur in das Forschungsinformationssystem synchron zu der Struktur im parallel eingeführten IDM zu gewährleisten ist. Aufgrund der Komplexität der Struktur, der Vielzahl an Organisationseinheiten an der JGU und der fortlaufenden Änderungen bei der Zuordnung von Personen zu Organisationseinheiten stößt die Synchronisationsmöglichkeit von IDM und FIS bisher an ihre Grenzen. Bisherige Anwendungen der Softwarelösung beruhen darauf, dass die Organisationsstruktur manuell im System angelegt und gepflegt wird oder Eigenentwicklungen auf Grundlage der Programmierschnittstelle (API) des FIS implementiert wurden. Da beide Szenarien für die JGU nicht in Betracht kommen, wird aktuell gemeinsam mit dem Anbieter an einer Übergangslösung gearbeitet. Dabei werden mit einem initialen Einmalimport Organisationsdaten der relativ statischen höheren Ebenen in das FIS übernommen. Beim Export von Daten für die öffentliche Darstellung, z.B. der Publikationslisten auf Fachbereichs- oder Institutswebseiten, werden die Daten aus dem FIS mit den feingranularen Organisationdaten aus dem IDM über eine interne Eigenentwicklung miteinander verknüpft.
Datenexport für die Forschungsberichterstattung
Für den Aus- und Aufbau einer zentral angelegten Forschungsberichterstattung ist die regelmäßige Übernahme von Daten in das Data Warehouse (DWH) der JGU zu bestimmten Stichtagen geplant. Im DWH werden Daten aus verschiedenen operativen Systemen der JGU zusammengeführt und für Analysen und unterschiedliche Berichtszwecke bereitgestellt. Die Übernahme von Daten aus dem FIS in das DWH ist vorgesehen, um eine systematische Kopplung der Forschungsinformationen aus dem FIS mit bereits verfügbaren Informationen und Daten aus den Bereichen Drittmittel, Habilitationen, Promotionen und Personal/Stellen an einem Ort zu ermöglichen und auf diese Weise den internen und externen Anforderungen an die Forschungsberichterstattung einer Universität gerecht zu werden. Als Exportschnittstelle wird die Reporting Datenbank innerhalb des FIS genutzt, die bereits einige Reporting-Funktionen zur Verfügung stellt. Die Transformation der Daten entlang der Spezifikation des Kerndatensatz Forschung soll bei der Datenübernahme in das DWH durch den ETL-Prozess erfolgen, bei dem Daten aus mehreren unterschiedlich strukturierten Datenquellen in einer Zieldatenbank zusammengeführt werden.
Erste Bilanz und Ausblick
Inzwischen wurde das System in einer ersten Pilotphase mit Wissenschaftler*innen eines naturwissenschaftlichen Fachbereichs getestet, in einer aktuell laufenden zweiten Pilotphase werden jetzt die Nutzer*innen der abgelösten Hochschulbibliographie in den aktiven Nutzerkreis einbezogen. Das aus den Pilotphasen resultierende Feedback wird dazu genutzt, den Support für das System zu verbessern und die Konfiguration der Nutzeroberfläche weiter an die gelebte Praxis an der JGU anzupassen.
Nach den bisherigen Rückmeldungen besteht insgesamt nur wenig Anpassungsbedarf an der Oberfläche des FIS. Insgesamt ist diese – mit den persönlichen Profil- und Übersichtsseiten, einer klar strukturierten und überschaubaren Menü-Navigation – intuitiv verständlich. Das Fehlen einer deutschsprachigen Oberfläche konnte gut über das Support-Angebot aus deutsch- und englischsprachigen Handreichungen, FAQs, Video-Tutorials und individuellen Terminvereinbarungen kompensiert werden.
In einer begleitenden Nutzerumfrage, die drei Monate nach dem Kick-Off zur ersten Pilotphase durchgeführt wurde, konnte festgehalten werden, welche Anforderungen und Schwierigkeiten sich aus der wissenschaftlichen Praxis heraus ergeben. Dabei bestätigte sich unter anderem die Annahme, dass viele Forscher*innen die Möglichkeiten des Publikationsmanagements innerhalb des FIS als ausschlaggebend für ihre Bereitschaft ansehen, das System zu nutzen. Neben der automatisierten Datenübernahme aus externen Datenquellen wurde auch der Bedarf für den individuellen Import von Publikationslisten speziell aus CITAVI und INSPIRE deutlich. Andere Nutzer*innen merkten Schwierigkeiten bei der Nutzung der Suchfunktion im System an. Auf der Projektwebsite werden entsprechende Erklärvideos und Hilfestellungen bereitgestellt. Ein häufig geäußerter Wunsch bezieht sich auf funktionale Erweiterungen der ersten Version des WordPress-Plugins für die Darstellung auf Webseiten. Das Feedback der Anwender*innen wird im laufenden Prozess der Weiterentwicklung für die Anforderungsdefinition genutzt. Die Umsetzung wird im Rahmen der Möglichkeiten schrittweise erfolgen.
Die Durchführung einer weiteren Pilotphase mit einem geistes- oder sozialwissenschaftlichen Fachbereich ist in Vorbereitung und soll dazu dienen, weitere fachspezifische Anforderungen kennenzulernen und diese bei der campusweiten Systemeinführung und dem Ausbau des Support-Angebotes zu berücksichtigen. Die Darstellung von Inhalten aus dem FIS auf den Homepages der Forschenden zählt, ebenso wie die Nachnutzung von Projektinformationen aus der Finanzverwaltungssoftware und die Überführung erster Daten aus dem Forschungsinformationssystem in das Data Warehouse der JGU, zu den nächsten und abschließenden Meilensteinen im Projekt.
Autorinnen
Dieser Beitrag ist verfasst von Karin Eckert (Universitätsbibliothek) und Annabelle Gaßmann (Stabsstelle Planung und Controlling).